17:
108:, or finding example queries. Certain image features in example images may override the concept that the user is really focusing on. The traditional methods of image retrieval such as those used by libraries have relied on manually annotated images, which is expensive and time-consuming, especially given the large and constantly growing image databases in existence.
295:
1299:
1660:
1329:
1251:
1623:
1324:
846:
104:(CBIR) are that queries can be more naturally specified by the user. CBIR generally (at present) requires users to search by image concepts such as color and
1556:
1289:
498:
1284:
319:
188:
1319:
1665:
1387:
1140:
122:
384:
1404:
1424:
1334:
1304:
1294:
1274:
1244:
778:
1489:
1314:
1344:
337:
357:
Y Mori; H Takahashi & R Oka (1999). "Image-to-word transformation based on dividing and vector quantizing images with words.".
889:
239:
1494:
262:
152:
1479:
1237:
575:
C Cusano; G Ciocca & R Scettini (2004). Santini, Simone & Schettini, Raimondo (eds.). "Image
Annotation Using SVM".
474:
85:
techniques to attempt to automatically apply annotations to new images. The first methods learned the correlations between
1588:
1519:
1370:
132:
117:
101:
310:
1339:
1001:
Ilaria
Bartolini & Paolo Ciaccia (2007). "Imagination: Exploiting Link Analysis for Accurate Image Annotation".
509:
1536:
1449:
86:
67:
16:
1640:
1514:
984:
Changhu Wang; Feng Jing; Lei Zhang & Hong-Jiang Zhang (2007). "content-based image annotation refinement".
533:
1094:
940:
3rd ACM International
Multimedia Workshop on Automated Information Extraction in Media Production (AIEMPro10)
1576:
1566:
1309:
851:
Proceedings of the 27th annual international conference on
Research and development in information retrieval
1200:
1613:
1581:
1360:
362:
1618:
1429:
1375:
1038:
Emre Akbas & Fatos Y. Vural (2007). "Automatic Image
Annotation by Ensemble of Visual Descriptors".
847:"Automatic Image Annotation by Using Concept-Sensitive Salient Objects for Image Content Representation"
105:
93:
to try to translate the textual vocabulary with the 'visual vocabulary', or clustered regions known as
813:
Proceedings of the 2020 International
Conference on Computational Collective Intelligence (ICCCI 2020)
392:
1541:
1524:
1504:
1474:
1151:
584:
1040:
Intl. Conf. on
Computer Vision (CVPR) 2007, Workshop on Semantic Learning Applications in Multimedia
359:
Proceedings of the
International Workshop on Multimedia Intelligent Storage and Retrieval Management
305:
97:. Work following these efforts have included classification approaches, relevance models and so on.
1546:
1409:
1177:
524:
521:
441:
408:
367:
206:
90:
454:
20:
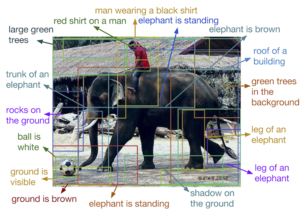
Output of DenseCap "dense captioning" software, analysing a photograph of a man riding an elephant
1561:
1469:
1454:
1414:
919:
816:
808:
600:
421:
226:
789:
709:
1499:
1444:
1396:
1118:"TagProp: Discriminative Metric Learning in Nearest Neighbor Models for Image Auto-Annotation"
959:
890:"Automated Image Annotation Using Global Features and Robust Nonparametric Density Estimation"
182:
70:
936:"Shiatsu: Semantic-based Hierarchical Automatic Tagging of Videos by Segmentation Using Cuts"
1608:
1571:
1419:
1279:
1110:
TagProp: Discriminative Metric
Learning in Nearest Neighbor Models for Image Auto-Annotation
1073:
1051:
1043:
1006:
989:
826:
694:
Proceedings of the 16th
Conference on Advances in Neural Information Processing Systems NIPS
671:
Proceedings of the ACM SIGIR Conference on Research and Development in Information Retrieval
592:
385:"Object recognition as machine translation: Learning a lexicon for a fixed image vocabulary"
218:
127:
82:
625:
Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition
1603:
1551:
1260:
1199:
Sarin, Supheakmungkol; Fahrmair, Michael; Wagner, Matthias & Kameyama, Wataru (2012).
972:
56:
52:
1117:
710:"Effective Automatic Image Annotation via A Coherent Language Model and Active Learning"
588:
1628:
1598:
1509:
1434:
1365:
1219:"Computer-Aided Medical Image Annotation: Preliminary Results With Liver Lesions in CT"
900:
866:
620:
250:
78:
74:
1202:
Leveraging Features from Background and Salient Regions for Automatic Image Annotation
1019:
935:
786:
Proceedings of the 2004 IEEE International Conference on Multimedia and Expo (ICME'04)
1654:
1593:
1218:
1116:
Matthieu Guillaumin and Thomas Mensink and Jakob Verbeek and Cordelia Schmid (2009).
273:
163:
48:
40:
867:"Modeling the shape of the scene: a holistic representation of the spatial envelope"
604:
1531:
955:
230:
556:
73:
with a very large number of classes - as large as the vocabulary size. Typically,
920:"Statistical Models of Video Structure for Content Analysis and Characterization"
830:
482:
1439:
1193:
Holistic Image Annotation using Salient Regions and Background Image Information
1010:
1024:
2nd ACM International Workshop on Keyword Search on Structured Data (KEYS 2010)
755:
732:
640:
686:
663:
455:"Automatic Linguistic Indexing of Pictures by a Statistical Modeling Approach"
44:
1047:
993:
809:"UIT-ViIC: A Dataset for the First Evaluation on Vietnamese Image Captioning"
664:"Automatic image annotation and retrieval using cross-media relevance models"
807:
Quan Hoang Lam; Quang Duy Le; Kiet Van Nguyen; Ngan Luu-Thuy Nguyen (2020).
534:"Supervised Learning of Semantic Classes for Image Annotation and Retrieval"
222:
60:
36:
740:
Proceedings of the International Conference on Image and Video Retrieval
1056:
240:"Image annotation : which approach for realistic databases ?"
596:
202:
1211:
Medical Image Annotation using bayesian networks and active learning
1205:. Journal of Information Processing. Vol. 20. pp. 250–266.
986:
IEEE Conference on Computer Vision and Pattern Recognition (CVPR 07)
756:"Multiple Bernoulli relevance models for image and video annotation"
1141:"Image Annotation Using Metric Learning in Semantic Neighbourhoods"
897:
Int'l Conf on Image and Video Retrieval (CIVR, Singapore, Jul 2005)
821:
1229:
971:
Changhu Wang; Feng Jing; Lei Zhang & Hong-Jiang Zhang (2006).
35:) is the process by which a computer system automatically assigns
15:
1176:
Venkatesh N. Murthy & Subhransu Maji and R. Manmatha (2015).
1133:
Image Annotation Using Metric Learning in Semantic Neighbourhoods
1178:"Automatic Image Annotation Using Deep Learning Representations"
960:"Image annotations by combining multiple evidence & wordNet"
1233:
679:
Relevance models using continuous probability density functions
422:"Learning-Based Linguistic Indexing of Pictures with 2-D MHMMs"
207:"Image Retrieval: Ideas, Influences, and Trends of the New Age"
89:
and training annotations, then techniques were developed using
1170:
Automatic Image Annotation Using Deep Learning Representations
1072:
Ameesh Makadia and Vladimir Pavlovic and Sanjiv Kumar (2008).
977:
14th Annual ACM International Conference on Multimedia (MM 06)
964:
13th Annual ACM International Conference on Multimedia (MM 05)
541:
IEEE Transactions on Pattern Analysis and Machine Intelligence
459:
IEEE Transactions on Pattern Analysis and Machine Intelligence
446:
IEEE Transactions on Pattern Analysis and Machine Intelligence
288:
1020:"Multi-dimensional Keyword-based Image Annotation and Search"
973:"Image annotation refinement using random walk with restarts"
934:
Ilaria Bartolini; Marco Patella & Corrado Romani (2010).
1032:
Automatic Image Annotation by Ensemble of Visual Descriptors
532:
G Carneiro; A B Chan; P Moreno & N Vasconcelos (2006).
383:
P Duygulu; K Barnard; N de Fretias & D Forsyth (2002).
882:
Global image features and nonparametric density estimation
763:
IEEE Conference on Computer Vision and Pattern Recognition
479:
Proceedings of International Conference on Computer Vision
389:
Proceedings of the European Conference on Computer Vision
247:
ACM International Conference on Image and Video Retrieval
59:
systems to organize and locate images of interest from a
1102:
Conf. on Computer Vision and Pattern Recognition (CVPR)
641:"Using Maximum Entropy for Automatic Image Annotation"
619:
R Maree; P Geurts; J Piater & L Wehenkel (2005).
100:
The advantages of automatic image annotation versus
1395:
1386:
1353:
1267:
648:
Int'l Conf on Image and Video Retrieval (CIVR 2004)
621:"Random Subwindows for Robust Image Classification"
1217:N. B. Marvasti & E. Yörük and B. Acar (2018).
1095:"Simultaneous Image Classification and Annotation"
777:J Y Pan; H-J Yang; P Duygulu; C Faloutsos (2004).
733:"An inference network approach to image retrieval"
263:"On the need for annotation-based image retrieval"
1223:IEEE Journal of Biomedical and Health Informatics
1093:Chong Wang and David Blei and Li Fei-Fei (2009).
1088:Simultaneous Image Classification and Annotation
687:"A model for learning the semantics of pictures"
613:Ensemble of Decision Trees and Random Subwindows
888:A Yavlinsky, E Schofield & S Rüger (2005).
442:"Real-time Computerized Annotation of Pictures"
409:"Real-time Computerized Annotation of Pictures"
475:"Learning the Semantics of Words and Pictures"
81:and the training annotation words are used by
1245:
1185:International Conference on Multimedia (ICMR)
1148:European Conference on Computer Vision (ECCV)
1081:European Conference on Computer Vision (ECCV)
1018:Ilaria Bartolini & Paolo Ciaccia (2010).
8:
754:S Feng; R Manmatha & V Lavrenko (2004).
685:V Lavrenko; R Manmatha & J Jeon (2003).
662:J Jeon; V Lavrenko & R Manmatha (2003).
270:Workshop on Information Retrieval in Context
1139:Yashaswi Verma & C. V. Jawahar (2012).
1392:
1252:
1238:
1230:
1055:
820:
434:Automatic linguistic indexing of pictures
366:
338:Learn how and when to remove this message
66:This method can be regarded as a type of
874:International Journal of Computer Vision
1661:Applications of artificial intelligence
144:
123:Object categorization from image search
1405:3D reconstruction from multiple images
1003:Springer Adaptive Multimedia Retrieval
918:N Vasconcelos & A Lippman (2001).
238:Nicolas Hervé; Nozha Boujemaa (2007).
187:: CS1 maint: archived copy as title (
180:
1425:Simultaneous localization and mapping
1125:Intl. Conf. on Computer Vision (ICCV)
1074:"A New Baseline for Image Annotation"
958:; Lei Wang & Mamoun Awad (2005).
927:IEEE Transactions on Image Processing
508:. pp. 3:993–1022. Archived from
7:
506:Journal of Machine Learning Research
497:D Blei; A Ng & M Jordan (2003).
1066:A New Baseline for Image Annotation
731:D Metzler & R Manmatha (2004).
555:R W Picard & T P Minka (1995).
1490:Automatic number-plate recognition
845:J Fan; Y Gao; H Luo; G Xu (2004).
481:. pp. 408–415. Archived from
14:
865:A Oliva & A Torralba (2001).
859:Relevant low-level global filters
491:Latent Dirichlet Allocation model
467:Hierarchical Aspect Cluster Model
391:. pp. 97–112. Archived from
377:Annotation as machine translation
1495:Automated species identification
293:
272:. pp. 44–46. Archived from
1666:Applications of computer vision
1480:Audio-visual speech recognition
748:Multiple Bernoulli distribution
557:"Vision Texture for Annotation"
473:K Barnard; D A Forsyth (2001).
201:Datta, Ritendra; Dhiraj Joshi;
1325:Recognition and categorization
708:R Jin; J Y Chai; L Si (2004).
1:
1589:Optical character recognition
1520:Content-based image retrieval
499:"Latent Dirichlet allocation"
133:Outline of object recognition
118:Content-based image retrieval
102:content-based image retrieval
831:10.1007/978-3-030-63007-2_57
779:"Automatic Image Captioning"
771:Multiple design alternatives
453:J Li & J Z Wang (2003).
440:J Li & J Z Wang (2008).
420:J Z Wang & J Li (2002).
407:J Li & J Z Wang (2006).
1011:10.1007/978-3-540-79860-6_3
948:Image Annotation Refinement
639:J Jeon; R Manmatha (2004).
313:. The specific problem is:
1682:
1485:Automatic image annotation
1320:Noise reduction techniques
315:long and multiline format.
309:to meet Knowledge (XXG)'s
25:Automatic image annotation
1637:
1450:Free viewpoint television
77:in the form of extracted
1515:Computer-aided diagnosis
1048:10.1109/CVPR.2007.383484
994:10.1109/CVPR.2007.383221
839:Natural scene annotation
351:Word co-occurrence model
205:; James Z. Wang (2008).
1577:Moving object detection
1567:Medical image computing
1330:Research infrastructure
1300:Image sensor technology
702:Coherent Language Model
569:Support Vector Machines
223:10.1145/1348246.1348248
29:automatic image tagging
1614:Video content analysis
1582:Small object detection
1361:Computer stereo vision
876:. pp. 42:145–175.
55:techniques is used in
51:. This application of
21:
1619:Video motion analysis
1430:Structure from motion
1376:3D object recognition
765:. pp. 1002–1009.
461:. pp. 1075–1088.
211:ACM Computing Surveys
160:i.yz.yamagata-u.ac.jp
19:
1542:Foreground detection
1525:Reverse image search
1505:Bioimage informatics
1475:Activity recognition
717:Proceedings of MM'04
426:Proc. ACM Multimedia
413:Proc. ACM Multimedia
320:improve this section
71:image classification
1609:Autonomous vehicles
1547:Gesture recognition
1410:2D to 3D conversion
966:. pp. 706–715.
853:. pp. 361–368.
673:. pp. 119–126.
627:. pp. 1:34–30.
589:2003SPIE.5304..330C
543:. pp. 394–410.
525:multiclass labeling
428:. pp. 436–445.
415:. pp. 911–920.
91:machine translation
33:linguistic indexing
1624:Video surveillance
1562:Landmark detection
1470:3D pose estimation
1455:Volumetric capture
1415:Gaussian splatting
1371:Object recognition
1285:Commercial systems
725:Inference networks
577:Internet Imaging V
561:Multimedia Systems
549:Texture similarity
515:on March 16, 2005.
401:Statistical models
22:
1648:
1647:
1557:Image restoration
1500:Augmented reality
1465:
1464:
1445:4D reconstruction
1397:3D reconstruction
1290:Feature detection
742:. pp. 42–50.
650:. pp. 24–32.
597:10.1117/12.526746
348:
347:
340:
311:quality standards
302:This section may
1673:
1572:Object detection
1537:Face recognition
1420:Shape from focus
1393:
1280:Digital geometry
1254:
1247:
1240:
1231:
1226:
1206:
1188:
1182:
1165:
1163:
1162:
1156:
1150:. Archived from
1145:
1128:
1122:
1105:
1099:
1084:
1078:
1061:
1059:
1027:
1014:
997:
980:
967:
943:
930:
929:. pp. 1–17.
924:
907:
905:
899:. Archived from
894:
877:
871:
854:
834:
824:
801:Image captioning
796:
794:
788:. Archived from
783:
766:
760:
743:
737:
720:
714:
697:
691:
674:
668:
656:Relevance models
651:
645:
628:
608:
564:
544:
538:
516:
514:
503:
486:
462:
449:
429:
416:
396:
372:
370:
343:
336:
332:
329:
323:
297:
296:
289:
280:
278:
267:
261:M Inoue (2004).
257:
255:
249:. Archived from
244:
234:
193:
192:
186:
178:
176:
174:
169:on 8 August 2014
168:
162:. Archived from
157:
149:
128:Object detection
83:machine learning
1681:
1680:
1676:
1675:
1674:
1672:
1671:
1670:
1651:
1650:
1649:
1644:
1633:
1604:Robotic mapping
1552:Image denoising
1461:
1382:
1349:
1315:Motion analysis
1263:
1261:Computer vision
1258:
1216:
1198:
1180:
1175:
1160:
1158:
1154:
1143:
1138:
1120:
1115:
1097:
1092:
1076:
1071:
1037:
1017:
1000:
983:
970:
953:
933:
922:
917:
912:Video semantics
903:
892:
887:
869:
864:
844:
806:
792:
781:
776:
758:
753:
735:
730:
712:
707:
689:
684:
666:
661:
643:
638:
633:Maximum Entropy
618:
574:
554:
536:
531:
512:
501:
496:
472:
452:
439:
419:
406:
382:
356:
344:
333:
327:
324:
317:
298:
294:
287:
285:Further reading
276:
265:
260:
253:
242:
237:
200:
197:
196:
179:
172:
170:
166:
155:
153:"Archived copy"
151:
150:
146:
141:
114:
79:feature vectors
57:image retrieval
53:computer vision
39:in the form of
27:(also known as
12:
11:
5:
1679:
1677:
1669:
1668:
1663:
1653:
1652:
1646:
1645:
1638:
1635:
1634:
1632:
1631:
1629:Video tracking
1626:
1621:
1616:
1611:
1606:
1601:
1599:Remote sensing
1596:
1591:
1586:
1585:
1584:
1579:
1569:
1564:
1559:
1554:
1549:
1544:
1539:
1534:
1529:
1528:
1527:
1517:
1512:
1510:Blob detection
1507:
1502:
1497:
1492:
1487:
1482:
1477:
1472:
1466:
1463:
1462:
1460:
1459:
1458:
1457:
1452:
1442:
1437:
1435:View synthesis
1432:
1427:
1422:
1417:
1412:
1407:
1401:
1399:
1390:
1384:
1383:
1381:
1380:
1379:
1378:
1368:
1366:Motion capture
1363:
1357:
1355:
1351:
1350:
1348:
1347:
1342:
1337:
1332:
1327:
1322:
1317:
1312:
1307:
1302:
1297:
1292:
1287:
1282:
1277:
1271:
1269:
1265:
1264:
1259:
1257:
1256:
1249:
1242:
1234:
1228:
1227:
1213:
1212:
1208:
1207:
1195:
1194:
1190:
1189:
1172:
1171:
1167:
1166:
1135:
1134:
1130:
1129:
1112:
1111:
1107:
1106:
1086:
1085:
1068:
1067:
1063:
1062:
1034:
1033:
1029:
1028:
1015:
998:
981:
968:
950:
949:
945:
944:
931:
914:
913:
909:
908:
906:on 2005-12-20.
884:
883:
879:
878:
861:
860:
856:
855:
841:
840:
836:
835:
803:
802:
798:
797:
795:on 2004-12-09.
773:
772:
768:
767:
750:
749:
745:
744:
727:
726:
722:
721:
704:
703:
699:
698:
681:
680:
676:
675:
658:
657:
653:
652:
635:
634:
630:
629:
615:
614:
610:
609:
571:
570:
566:
565:
551:
550:
546:
545:
528:
527:
518:
517:
493:
492:
488:
487:
485:on 2007-09-28.
469:
468:
464:
463:
450:
436:
435:
431:
430:
417:
403:
402:
398:
397:
395:on 2005-03-05.
379:
378:
374:
373:
368:10.1.1.31.1704
353:
352:
346:
345:
301:
299:
292:
286:
283:
282:
281:
279:on 2014-08-08.
258:
256:on 2011-05-20.
235:
195:
194:
143:
142:
140:
137:
136:
135:
130:
125:
120:
113:
110:
87:image features
75:image analysis
13:
10:
9:
6:
4:
3:
2:
1678:
1667:
1664:
1662:
1659:
1658:
1656:
1643:
1642:
1641:Main category
1636:
1630:
1627:
1625:
1622:
1620:
1617:
1615:
1612:
1610:
1607:
1605:
1602:
1600:
1597:
1595:
1594:Pose tracking
1592:
1590:
1587:
1583:
1580:
1578:
1575:
1574:
1573:
1570:
1568:
1565:
1563:
1560:
1558:
1555:
1553:
1550:
1548:
1545:
1543:
1540:
1538:
1535:
1533:
1530:
1526:
1523:
1522:
1521:
1518:
1516:
1513:
1511:
1508:
1506:
1503:
1501:
1498:
1496:
1493:
1491:
1488:
1486:
1483:
1481:
1478:
1476:
1473:
1471:
1468:
1467:
1456:
1453:
1451:
1448:
1447:
1446:
1443:
1441:
1438:
1436:
1433:
1431:
1428:
1426:
1423:
1421:
1418:
1416:
1413:
1411:
1408:
1406:
1403:
1402:
1400:
1398:
1394:
1391:
1389:
1385:
1377:
1374:
1373:
1372:
1369:
1367:
1364:
1362:
1359:
1358:
1356:
1352:
1346:
1343:
1341:
1338:
1336:
1333:
1331:
1328:
1326:
1323:
1321:
1318:
1316:
1313:
1311:
1308:
1306:
1303:
1301:
1298:
1296:
1293:
1291:
1288:
1286:
1283:
1281:
1278:
1276:
1273:
1272:
1270:
1266:
1262:
1255:
1250:
1248:
1243:
1241:
1236:
1235:
1232:
1224:
1220:
1215:
1214:
1210:
1209:
1204:
1203:
1197:
1196:
1192:
1191:
1186:
1179:
1174:
1173:
1169:
1168:
1157:on 2013-05-14
1153:
1149:
1142:
1137:
1136:
1132:
1131:
1126:
1119:
1114:
1113:
1109:
1108:
1103:
1096:
1091:
1090:
1089:
1082:
1075:
1070:
1069:
1065:
1064:
1058:
1053:
1049:
1045:
1041:
1036:
1035:
1031:
1030:
1025:
1021:
1016:
1012:
1008:
1004:
999:
995:
991:
987:
982:
978:
974:
969:
965:
961:
957:
952:
951:
947:
946:
941:
937:
932:
928:
921:
916:
915:
911:
910:
902:
898:
891:
886:
885:
881:
880:
875:
868:
863:
862:
858:
857:
852:
848:
843:
842:
838:
837:
832:
828:
823:
818:
814:
810:
805:
804:
800:
799:
791:
787:
780:
775:
774:
770:
769:
764:
757:
752:
751:
747:
746:
741:
734:
729:
728:
724:
723:
718:
711:
706:
705:
701:
700:
695:
688:
683:
682:
678:
677:
672:
665:
660:
659:
655:
654:
649:
642:
637:
636:
632:
631:
626:
622:
617:
616:
612:
611:
606:
602:
598:
594:
590:
586:
582:
578:
573:
572:
568:
567:
562:
558:
553:
552:
548:
547:
542:
535:
530:
529:
526:
523:
520:
519:
511:
507:
500:
495:
494:
490:
489:
484:
480:
476:
471:
470:
466:
465:
460:
456:
451:
447:
443:
438:
437:
433:
432:
427:
423:
418:
414:
410:
405:
404:
400:
399:
394:
390:
386:
381:
380:
376:
375:
369:
364:
360:
355:
354:
350:
349:
342:
339:
331:
328:November 2022
321:
316:
312:
308:
307:
300:
291:
290:
284:
275:
271:
264:
259:
252:
248:
241:
236:
232:
228:
224:
220:
216:
212:
208:
204:
199:
198:
190:
184:
165:
161:
154:
148:
145:
138:
134:
131:
129:
126:
124:
121:
119:
116:
115:
111:
109:
107:
103:
98:
96:
92:
88:
84:
80:
76:
72:
69:
64:
62:
58:
54:
50:
49:digital image
46:
42:
38:
34:
30:
26:
18:
1639:
1532:Eye tracking
1484:
1388:Applications
1354:Technologies
1340:Segmentation
1222:
1201:
1184:
1159:. Retrieved
1152:the original
1147:
1124:
1101:
1087:
1080:
1039:
1023:
1002:
985:
976:
963:
956:Latifur Khan
939:
926:
901:the original
896:
873:
850:
812:
790:the original
785:
762:
739:
716:
693:
670:
647:
624:
580:
576:
560:
540:
510:the original
505:
483:the original
478:
458:
445:
425:
412:
393:the original
388:
358:
334:
325:
318:Please help
314:
303:
274:the original
269:
251:the original
246:
214:
210:
171:. Retrieved
164:the original
159:
147:
99:
94:
65:
32:
28:
24:
23:
1440:Visual hull
1335:Researchers
1057:11511/16027
954:Yohan Jin;
583:: 330–338.
322:if you can.
217:(2): 1–60.
68:multi-class
1655:Categories
1310:Morphology
1268:Categories
1161:2014-02-26
822:2002.00175
522:Supervised
173:13 January
139:References
41:captioning
363:CiteSeerX
1345:Software
1305:Learning
1295:Geometry
1275:Datasets
605:16246057
304:require
183:cite web
112:See also
61:database
45:keywords
37:metadata
585:Bibcode
306:cleanup
231:7060187
106:texture
603:
365:
229:
203:Jia Li
1181:(PDF)
1155:(PDF)
1144:(PDF)
1121:(PDF)
1098:(PDF)
1077:(PDF)
923:(PDF)
904:(PDF)
893:(PDF)
870:(PDF)
817:arXiv
793:(PDF)
782:(PDF)
759:(PDF)
736:(PDF)
713:(PDF)
690:(PDF)
667:(PDF)
644:(PDF)
601:S2CID
537:(PDF)
513:(PDF)
502:(PDF)
277:(PDF)
266:(PDF)
254:(PDF)
243:(PDF)
227:S2CID
167:(PDF)
156:(PDF)
95:blobs
47:to a
581:5304
189:link
175:2022
1052:hdl
1044:doi
1007:doi
990:doi
827:doi
593:doi
219:doi
43:or
31:or
1657::
1221:.
1183:.
1146:.
1123:.
1100:.
1079:.
1050:.
1042:.
1022:.
1005:.
988:.
975:.
962:.
938:.
925:.
895:.
872:.
849:.
825:.
815:.
811:.
784:.
761:.
738:.
715:.
692:.
669:.
646:.
623:.
599:.
591:.
579:.
559:.
539:.
504:.
477:.
457:.
444:.
424:.
411:.
387:.
361:.
268:.
245:.
225:.
215:40
213:.
209:.
185:}}
181:{{
158:.
63:.
1253:e
1246:t
1239:v
1225:.
1187:.
1164:.
1127:.
1104:.
1083:.
1060:.
1054::
1046::
1026:.
1013:.
1009::
996:.
992::
979:.
942:.
833:.
829::
819::
719:.
696:.
607:.
595::
587::
563:.
448:.
371:.
341:)
335:(
330:)
326:(
233:.
221::
191:)
177:.
Text is available under the Creative Commons Attribution-ShareAlike License. Additional terms may apply.